A blog post on linear regression and some experiments involving modifications like the LASSO Regularization
Author
Eduardo Pareja Lema
Published
March 26, 2023
Goal
The goal of this blog is to mainly show two different ways of implementing linear regression. First, we implement the following analytical formula \[ \vec{w} = (X^TX)^{-1}X^Ty\,\,,\] which explicitly gives a value for \(\vec{w}\). This formula is derived using some linear algebra to solve the equation \(\nabla L(\vec{w}) = 0\), which must hold at a minimum. Even though this formula provides a straightforward way to find \(\vec{w}\), it is not the most efficient. Therefore, a gradient descent method is also implemented.
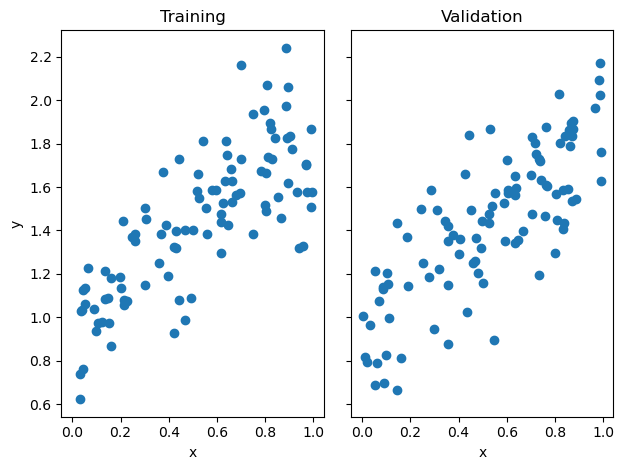
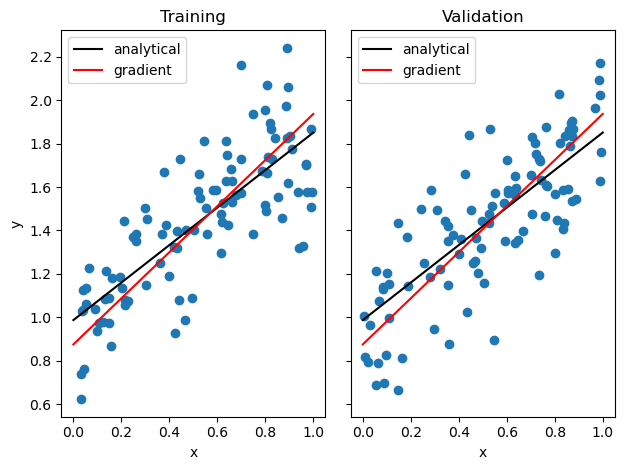
Now, we print the scores and draw the lines from the resulting weights of both models implemented:
LR = LinearRegression()LR.fit_analytical(X_train, y_train) # I used the analytical formula as my default fit methodprint(f"Training score (Analytical) = {LR.score(X_train, y_train).round(4)}")print(f"Validation score (Analytical) = {LR.score(X_val, y_val).round(4)}")LR2 = LinearRegression()LR2.fit_gradient(X_train, y_train, alpha =0.0005) print(f"Training score (Gradient)= {LR2.score(X_train, y_train).round(4)}")print(f"Validation score (Gradient) = {LR2.score(X_val, y_val).round(4)}")#Plot both analytical and gradient descent results x = np.linspace(0, 1, 101)y_analytical = (LR.w[0]*x + LR.w[1])y_gradient = (LR2.w[0]*x + LR2.w[1])fig, axarr = plt.subplots(1, 2, sharex =True, sharey =True)axarr[0].scatter(X_train, y_train)axarr[1].scatter(X_val, y_val)#print linesaxarr[0].plot(x, y_analytical, color="black", label="analytical")axarr[1].plot(x, y_analytical, color="black", label="analytical")axarr[0].plot(x, y_gradient, color="red", label="gradient")axarr[1].plot(x, y_gradient, color="red", label="gradient")axarr[0].legend(loc="best")axarr[1].legend(loc="best")labs = axarr[0].set(title ="Training", xlabel ="x", ylabel ="y")labs = axarr[1].set(title ="Validation", xlabel ="x")plt.tight_layout()
Training score (Analytical) = 0.6114
Validation score (Analytical) = 0.6243
Training score (Gradient)= 0.5788
Validation score (Gradient) = 0.6177
We see how both implementations lead to the similar results. The analytical formula seems to me slightly better, this is probably due to the learning rate of the gradient descent or the number of iterations.
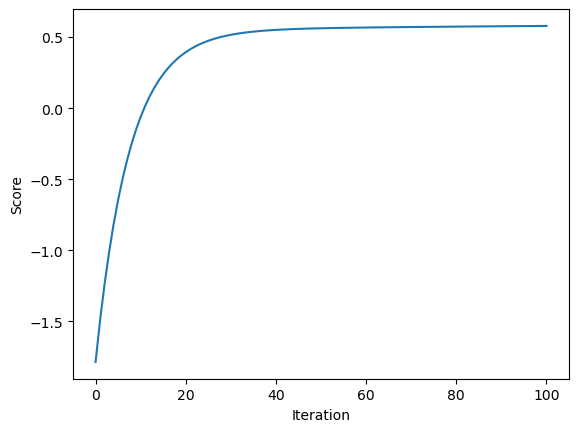
Now, to make sure the implementation of gradient descent is correct, let us visualize the how the score changed over time. The score should increase monotonically, and it does:
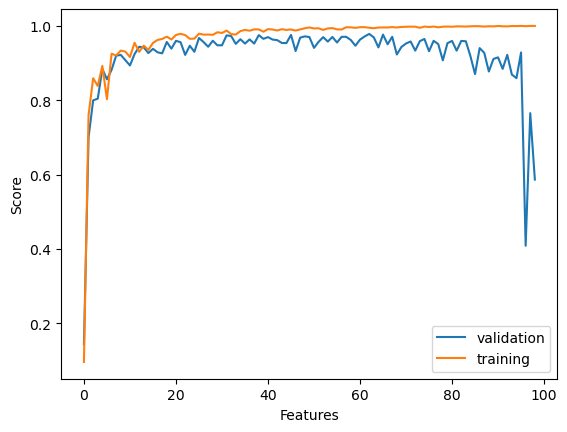
What if we increaase the number of features? Our model would have more data points so we should expect to produce a better training score as the number of features increase. However, would this lead to overfitting? Well, let’s perform an experiment that allow us to visualize the change in both the trainig and validation score.
Just as predicted, the training score seems to approach 1 as the numer of features increase. However, the validation score clearly decreases after some point, which suggests that increasing the number of features leads to overfitting.
We now run the same experiment but with the LASSO algorithm. This algorithm uses a modified loss function with a regularization term \(\alpha\):
We observe that the LASSO algorithm reaches a better accuracy than the regular linear regression, as it quickly gets close to 1. However, we observe the same overfitting trend. The regularization strenght seems to affect how the validation score drops, a smaller alpha seems to be better for overfitted models.